|
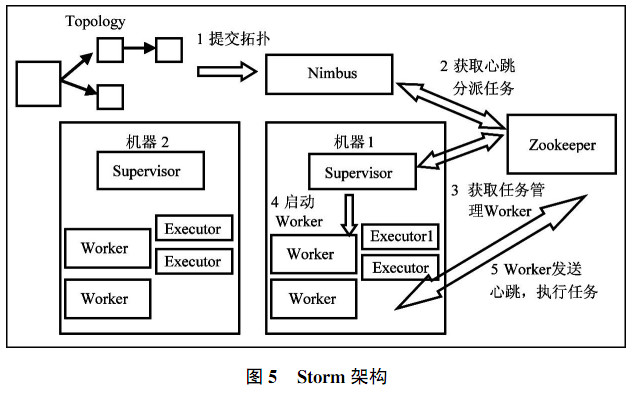
1.2 Storm 2011年,Hadoop憑借著高吞吐,方便處理海量數據的優勢奠定其在大數據的主要地位。Hadoop專注于大規模數據存儲和處理,但是Hadoop的MapReduce延遲大,響應緩慢,運維復雜,不適用于實時大數據方面。針對業務場景中對秒級別甚至毫秒級別響應的需求,Twitter公司推出開源分布式、容錯的實時流計算系統Storm,解決了大規模數據實時處理的問題。Storm是一個分布式的、容錯的實時計算系統,適用于計算機集群中編寫與擴展復雜的實時計算。 Storm集群由一個主節點和多個工作節點組成,Storm架構圖如圖5所示。主節點運行Nimbus守護進程,用于分配代碼、布置任務及故障檢測。每個工作節點運行Supervisor守護進程,開始并終止工作進程。ZooKeeper用于管理集群中的不同組件,協調Nimbus和Supervisor兩者的工作,topology是由計算節點組成的圖,節點包括處理的邏輯。 Storm的工作過程是Nimbus針對該拓撲建立本地的目錄,根據topology的配置計算作業、分配作業,在zookeeper上建立任務節點assignments存儲作業task和supervisor機器節點中worker的對應關系,以及創建作業節點taskbeats來監控作業的心跳,啟動topology。Supervisor從zookeeper上獲取分配的作業task,啟動多個worker,worker生成作業task,一個作業task一個線程;根據topology信息初始化建立作業task之間的連接;作業和作業之間通過可嵌入的網絡通訊庫管理,最后整個拓撲運行起來。 Storm有很多的優勢。第一,簡單的編程模型。Storm降低實時處理的復雜性。第二,可以使用各種編程語言。Storm默認支持Clojure、Java、Ruby和Python。通過實現一個簡單的Storm通信協議,可增加對其他語言的支持。第三,容錯性。Storm管理工作進程和節點的故障。第四,水平擴展。計算在多個線程、進程和服務器之間并行進行。第五,可靠的消息處理。Storm保證每個消息至少能得到一次完整處理。第六,快速。系統的設計使用網絡通訊庫作為其底層消息隊列,保證消息能得到快速的處理。第七,本地模式。Storm“本地模式”可在處理過程中完全模擬Storm集群,可快速進行開發和單元測試。 Storm也存在一些亟待解決的問題。第一,目前的開源版本中只是單節點Nimbus,故障只能自動重啟,可考慮實現一個雙Nimbus的布局。第二,Clojure是一個在Java虛擬機平臺運行的動態函數式編程語言,優勢在于流程計算,Storm的部分核心內容由Clojure編寫,性能提高的同時也提升維護成本。因此,Storm適合用于需要實時分析的農業數據,如農業大棚中的溫度、濕度監測等,可以迅速地分析出結果。
|